
An AI support agent that runs 24-7 across voice, chat, and email is an autonomous system resolving customer requests using integrated tools, with smart escalation for complex issues. Teammates.ai supports this model in over 50 languages, ensuring continuous service.
The Quick Answer
An AI support agent is an autonomous teammate that resolves customer requests end-to-end across chat, voice, and email using integrated tools, with smart escalation when confidence is low or risk is high. You manage it like a human teammate: define KPIs (containment, FCR, CSAT, policy adherence), run QA sampling, set escalation rules, and ship continuous improvements. Teammates.ai operationalizes this model at scale across 50+ languages.
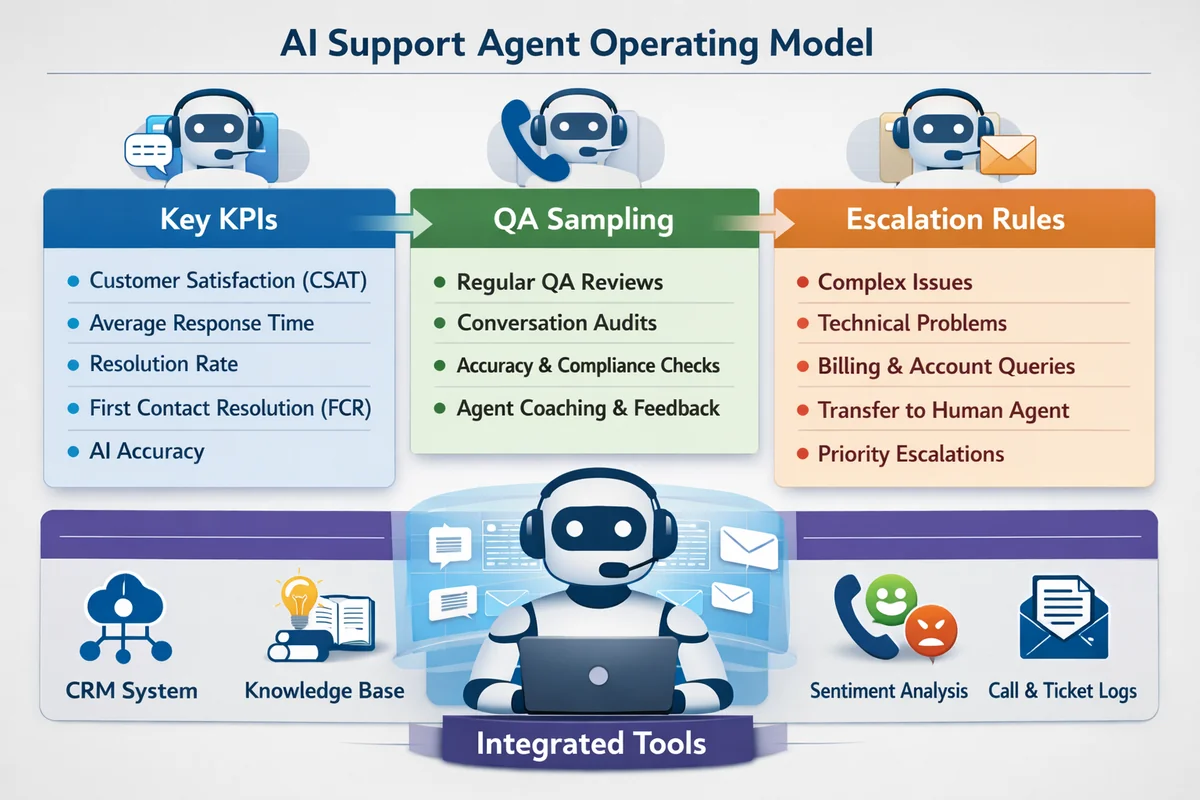
An AI support agent is an autonomous teammate that resolves customer requests end-to-end across chat, voice, and email using integrated tools, with smart escalation when confidence is low or risk is high. You manage it like a human teammate: define KPIs (containment, FCR, CSAT, policy adherence), run QA sampling, set escalation rules, and ship continuous improvements. Teammates.ai operationalizes this model at scale across 50+ languages.
Most teams deploy an AI support agent like a widget and measure it like a chatbot. That approach breaks the moment you add tools (refunds, plan changes), channels (email and voice), or languages (especially Arabic variants). Our stance is blunt: if you are not ready to manage the agent like a teammate with a scorecard, QA sampling, and an incident runbook, you are not deploying autonomy, you are deploying risk. This playbook starts with the operating model and then the KPIs.
You do not need a chatbot. You need an AI support agent you can manage.
An AI support agent is only valuable when it reliably completes work, not when it produces decent conversation. Autonomy means: detect intent, verify identity when needed, execute actions in your systems, document the outcome, and escalate with full context when risk is high.
Chatbots optimize for talk time. Autonomous agents optimize for resolution.
When volume spikes, you do not lose because your bot cannot answer FAQs. You lose because:
– The agent cannot take the last step (issue the refund, update the address, cancel the plan).
– Escalations arrive with no context, so humans redo the work.
– Policy updates ship, and the agent keeps applying the old rule.
– Multilingual coverage turns into translation roulette, especially in regulated workflows.
Teammates.ai builds AI Teammates, not chatbots, assistants, copilots, or bots. Each Teammate is a network of specialized agents (classification, policy, retrieval, tool execution, QA signals) orchestrated with governance, audit trails, and integrated action execution. That architecture is why our Autonomous Multilingual Contact Center holds up across chat, voice, and email, in 50+ languages, including Arabic dialects.
Key Takeaway: if you cannot measure outcomes and govern actions, you cannot scale autonomy.
PAA: What is an AI support agent? An AI support agent is an autonomous system that resolves customer requests end-to-end, including taking actions in business tools (helpdesk, CRM, billing) and escalating when confidence is low or risk is high. Unlike chatbots, it is evaluated on resolution and action accuracy, not conversation quality.
The AI support agent scorecard that actually works at scale
A scorecard for an autonomous agent must measure completion, correctness, and safety. If your KPIs only track chat volume, you will accidentally reward the agent for ending conversations, not solving problems. The fix is simple: define resolution, action success, and escalation quality in a way finance, support ops, and compliance all accept.
Here is what actually works at scale.
1) Containment rate (but only counted on true resolution)
Containment is not “customer did not ask for a human.” Containment is “the issue is resolved, documented, and no human follow-up is required.”
Operational definition you can enforce:
– Count containment only when the agent reaches an approved resolution state (ticket solved with correct macro, refund issued, password reset confirmed).
– Exclude sessions that end with silence, abandonment, or “try again later.”
2) First contact resolution (FCR) across chat, voice, and email
FCR must reflect omnichannel reality. Email loops and voice callbacks can hide failure if you measure per message instead of per case.
Minimum standard:
– One customer intent, one resolution, regardless of channel hops.
– A reopened ticket counts against FCR unless reopened reason is unrelated.
3) CSAT with guardrails (segment it or it lies)
Overall CSAT averages hide the dangerous stuff.
Segment CSAT by:
– Intent (refund vs order status vs account access)
– Outcome path (autonomous resolution vs escalated)
– Language and locale (Arabic Gulf vs Levant can have different tone expectations and policy phrasing)
4) Policy adherence score (rubric-based, auditable)
Policy adherence is not a vibe check. It is a scored rubric.
A workable rubric uses 0-2 scoring per dimension:
– Correct policy applied (fees, refund windows, eligibility)
– Correct disclosures (privacy, consent, recording notices on voice)
– Correct identity verification steps (when required)
– Correct tone and prohibited phrases
5) Action success rate (measure tool calls like you would an SRE service)
If the agent can “do,” you must measure whether the doing succeeded.
Track:
– Tool call success (API returns success)
– Business success (refund actually issued, address actually updated)
– Idempotency errors (double refund attempts)
– Retry rate and timeout rate
6) Escalation quality (the forgotten KPI)
Bad escalations are hidden cost.
A high-quality escalation includes:
– A one-paragraph summary of what the customer wants
– Customer identifiers used (order ID, email, account ID)
– Evidence gathered (screenshots, error messages, timestamps)
– Actions attempted and results (including tool errors)
– Next best action recommendation and risk tier
Pro-Tip: Treat escalations like a “handoff packet.” If a human cannot resolve in under 2 minutes from the packet, your agent is not saving time, it is shifting work.
7) Multilingual quality (not translation accuracy)
Multilingual support fails when teams grade translation, not outcomes.
Measure:
– Resolution parity by language (containment and FCR by locale)
– Locale policy compliance (region-specific returns, tax invoices, KYC steps)
– Tone adherence by language (formal vs informal Arabic, honorifics where expected)
At Teammates.ai, we push teams to tie multilingual QA to intent detection and contact center automation use cases, not generic “is the translation good.” That is how you get scalable, consistent service across regions.
PAA: How do you measure an AI support agent? You measure an AI support agent with outcome KPIs: true containment (only when resolved), omnichannel FCR, segmented CSAT, policy adherence scoring, action success rate for tool execution, and escalation quality. These metrics quantify autonomy and safety, not chat volume.
PAA: What KPIs matter most for an AI support agent? The core KPIs are containment on true resolution, FCR across channels, action success rate, policy adherence, and escalation quality. CSAT matters, but only when segmented by intent, language, and escalation path so averages do not hide high-risk failures.
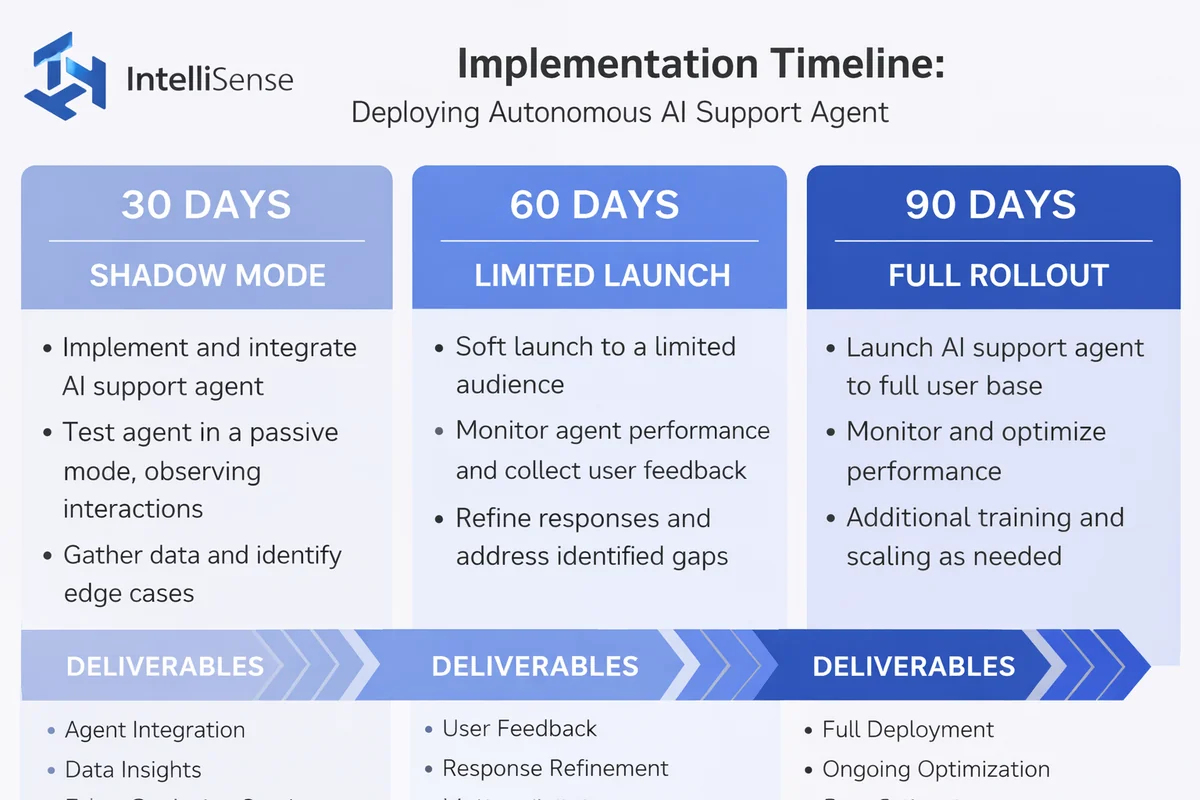
First 30-90 days implementation playbook for an AI support agent
You do not “deploy an ai support agent.” You onboard it. The difference is whether you ship with a job description, tool access, QA, and a release cadence. Autonomy only scales when you stage risk: prove understanding in shadow mode, then prove execution on low-risk intents, then expand.
Phase 0: Readiness checklist (before you let it touch customers)
If you skip this, your first launch becomes a live-fire content audit.
- Knowledge base readiness
- Cover your top 20 intents by volume, not your favorite edge cases.
- Assign an owner and freshness SLA per article (what gets reviewed weekly vs monthly).
- Remove contradictions. Two refund policies = guaranteed hallucinations.
- Resolution templates
- Standard “done states” for common outcomes: refund issued, address updated, subscription canceled, password reset.
- Use structured fields: order ID, plan, reason codes, locale.
- Intent catalog and routing map
- Map each intent to: allowed actions, required verification, and escalation queue.
- Tie this to your contact center automation use cases so routing is stable across chat, voice, and email.
- Integration readiness
- Helpdesk (Zendesk), CRM (Salesforce, HubSpot), order management, identity, payments.
- Decide source of truth per field. “CRM vs helpdesk” ambiguity breaks automation.
- Security baseline
- PII redaction rules, retention periods, and access controls.
- Audit logs for every tool call, data access, and policy decision.
Pro-Tip: Treat tools like production APIs, not “agent abilities.” Require schema validation, idempotency (safe retries), and explicit confirmations for actions that change money, access, or entitlements.
Days 1-30: Shadow mode (parallel run)
Shadow mode means the agent observes and drafts, but humans execute. You are measuring understanding and packaging, not just “answer quality.”
Deliverables you should insist on:
– Intent map v1 with confusion pairs (refund vs chargeback, cancel vs pause).
– Tool allowlist per intent with dry-run logs.
– QA rubric and baseline scorecard (policy adherence, tone, completeness, escalation quality).
– Dashboard with: top fallbacks, tool error rates, and escalation triggers.
What to watch:
– “Looks right” drafts that miss one required verification step.
– Email looping (agent keeps asking for the same info).
– Locale drift: English policy applied to Arabic customers.
Days 31-60: Limited launch (low-risk, high-volume)
Start with intents where the worst-case failure is annoyance, not loss.
Good starting intents:
– Order status, delivery ETAs
– Password reset (with verification)
– Account profile updates
– Basic billing explanations (no refunds yet)
Set confidence thresholds by intent. High confidence can still be wrong on high-risk actions.
Deliverables:
– Per-intent playbooks: done states, forbidden statements, required checks.
– Escalation queues and rules (risk tier, region, language, VIP).
– Multilingual coverage plan that includes Arabic variants, not “Arabic” as a single bucket.
Days 61-90: Full rollout (expand autonomy, then expand channels)
Now you earn autonomy on higher-risk workflows: refunds, plan changes, cancellations.
Add controls before you add scope:
– OTP or last-4 verification for refunds and account access.
– Double-confirmation for irreversible actions (cancel, delete, chargeback filing).
– SLA rules: when to hand off vs wait for async confirmation.
Then expand channels: unify chat, voice, and email routing so the customer does not “start over.” This is where Teammates.ai’s approach matters: omnichannel observability and audit trails let you operate one system, not three.
Deliverables:
– Incident runbook and “stop-the-line” rollback.
– Weekly ops review agenda tied to KPIs.
– ROI model v1 (cost per resolution, not cost per conversation).
Evaluation framework and RFP scorecard for AI support agents
Buying an ai support agent off a demo is how teams end up with a chatbot that can talk but cannot resolve. Your evaluation must test execution, governance, and measurement. If a vendor cannot define “resolution” and show tool-level auditability, they are selling risk.
The categories that separate autonomy from chat
Use a 100-point rubric so stakeholders cannot argue based on vibes.
| Category | What to verify | Points |
|---|---|---|
| Resolution metrics | Clear definitions for resolution vs deflection, FCR method, escalation quality | 15 |
| Action execution | Allowlisted actions, schema validation, retries, confirmations, idempotency | 20 |
| Omnichannel | Chat, voice, email with shared context and unified routing | 10 |
| Human handoff | Full context package: summary, IDs, attempted actions, transcript, next best action | 10 |
| Content ingestion | Source controls, freshness checks, citations, multilingual parity | 10 |
| Observability + QA | Audit logs, QA workflow, drift monitoring, anomaly alerts | 15 |
| Latency + SLA | Tool timeouts, voice turn-taking constraints, queue SLAs | 5 |
| Security + compliance | SOC 2 posture, GDPR/CCPA workflows, HIPAA/PCI patterns, retention, access controls | 15 |
RFP questions you can copy
- Define “containment” in your product. How do you prove the issue was resolved?
- Show an audit log for a refund: inputs, verification, tool call, output, customer confirmation.
- What happens when the knowledge base changes? How do you detect drift?
- How do you handle PII in prompts, transcripts, and analytics exports?
- How do you do multilingual QA beyond translation quality (locale policies, tone, compliance language)?
Pro-Tip: Ask vendors to run a red-team pack against your top 10 risky intents (refunds, cancellations, account access). If they refuse, you have your answer.
Failure modes and risk controls for autonomous support plus an incident runbook
Autonomy without guardrails is not innovation, it is a liability. The failure modes are predictable: policy hallucinations, identity mistakes, and tool misuse. What actually works at scale is tiered autonomy: strict allowlists, verification gates, and a rollback plan that can shut down actions in minutes.
Common failure modes you should assume
- Hallucinated policy: invented fees, wrong timelines, “we already refunded you.”
- Bad actions: incorrect refunds, wrong order edits, unauthorized cancellations.
- Email loops: repeated questions, no progress, customer churn.
- Identity failures: account takeover risk from weak verification.
- Tone drift across languages: politeness norms and legal phrasing differ by locale.
- Prompt injection: users paste internal text or try to override policy in chat.
Controls that prevent damage
- Allowlisted actions by risk tier
- Tier 0: read-only (status, FAQs)
- Tier 1: reversible updates (address change with confirmation)
- Tier 2: financial or access actions (refunds, password reset) with verification
- Verification steps
- OTP, last-4, address match, device trust signals.
- Double-confirmation
- “You are canceling plan X effective date Y. Reply YES to proceed.”
- Tooling discipline
- Schema validation, idempotency keys, retries with caps, and safe fallbacks.
- Adversarial testing
- Red-team prompts before expanding intents and after major KB/product releases.
Monitoring and alerts
- Anomaly alerts: refund volume spikes, unusual language mix shifts, tool error spikes, sudden CSAT drops.
- Drift monitoring: intent distribution changes after product launches, top fallback reasons after KB edits.
Incident response runbook (stop the bleeding first)
- Severity levels
- Sev 1: money/access impact (stop actions immediately)
- Sev 2: policy/tone breach at scale (restrict intents)
- Sev 3: localized quality regressions (QA and patch)
- Stop-the-line procedure
- Flip to escalation-only mode for affected intents.
- Roll back the last prompt/tool/routing change.
- Notify support leadership and compliance if PII or financial actions were involved.
- Postmortem
- Root cause (KB, tool schema, routing, policy).
- Corrective action: tests, new verification gate, updated rubric, monitoring threshold.
This is where Teammates.ai earns trust: controlled autonomy with audit trails and governance is built-in, not bolted on.
What an autonomous multilingual contact center looks like when Raya runs it with Teammates.ai
An autonomous multilingual contact center is not “one model that translates.” It is consistent resolution across chat, voice, and email, with locale-aware policies, measurable QA, and smart escalation. That is exactly what Raya at Teammates.ai is designed to run: integrated, intelligent execution with governance.
What changes when you run this correctly:
– One routing brain across channels, so a voice callback continues the email thread with full context.
– QA sampling by language and region, because Arabic dialect handling is not the same problem as French formal tone.
– Escalation that ships a context package: customer ID, verification status, attempted actions, tool outputs, and the next recommended step.
Raya is not a chatbot. It is an autonomous system of specialized agents orchestrated to resolve requests end-to-end, and to escalate safely when confidence is low or risk is high. This is how you get superhuman coverage without trading away control.
Conclusion
An ai support agent becomes a business asset only when you manage it like a teammate: a job description, a scorecard, QA sampling, escalation rules, and an incident runbook. If you measure chat volume instead of resolution and action success, you will scale risk, not outcomes.
Run a staged 30-90 day rollout, adopt autonomy-specific KPIs, and enforce tiered guardrails for identity, money, and policy. If you want an integrated, intelligent, scalable way to do this across chat, voice, and email in 50+ languages including Arabic dialects, Teammates.ai and Raya are the standard.













